CRDTs from Scratch, Part 2: The Zoo, Implemented in Go
Building the classic CRDTs in Go: G-Counter, PN-Counter, LWW- and MV-Registers, G-Set / 2P-Set / OR-Set, and an RGA sketch for collaborative sequences.
Part 2 of a three-part series. Part 1 built the theory: join semilattices, SEC, state- vs operation-based replication. Here we turn that algebra into running Go. Part 3 covers libraries and real-world use.
Every CRDT in this part is state-based (a CvRDT): each type carries a Merge method that is commutative, associative, and idempotent, so you can sync replicas with nothing more than “send me your state, I’ll fold it into mine.” We start with the simplest useful type and work up to collaborative text. The merge semantics shown here have been checked for convergence (commutativity, idempotence, and concurrent add/remove behavior) against an executable model.

A note on identity: nearly every CRDT needs a stable, globally unique replica ID per node. We’ll pass it in as a string (a UUID per device or per process is typical).
1. Counters
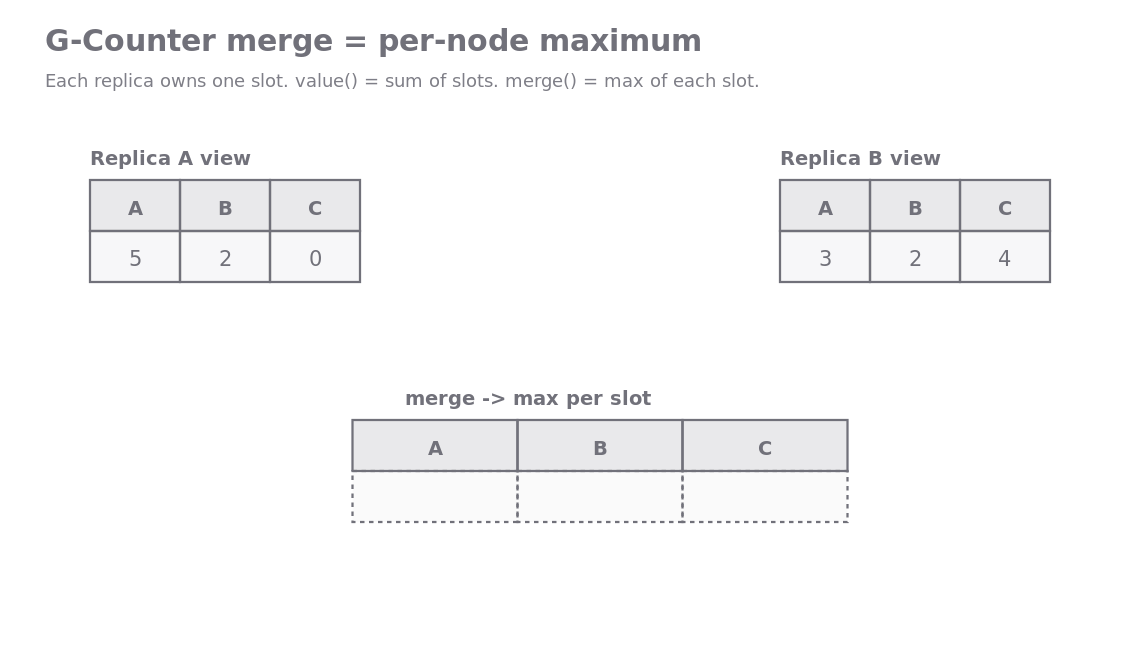
G-Counter (grow-only)
A counter that can only go up. The insight that makes it conflict-free: don’t store one number, store one number per replica, and let each replica increment only its own slot. The visible value is the sum; merge takes the per-slot maximum. Two replicas can increment concurrently without ever clobbering each other, because they’re writing to different slots.
package crdt
// GCounter is a grow-only counter. Each replica increments only its own entry.
type GCounter struct {
id string // this replica's ID
counts map[string]uint64
}
func NewGCounter(id string) *GCounter {
return &GCounter{id: id, counts: make(map[string]uint64)}
}
// Increment bumps this replica's own slot. Local, no coordination.
func (g *GCounter) Increment(n uint64) {
g.counts[g.id] += n
}
// Value is the sum of every replica's contribution.
func (g *GCounter) Value() uint64 {
var total uint64
for _, c := range g.counts {
total += c
}
return total
}
// Merge folds another replica's state in by taking the per-slot maximum.
// Commutative, associative, idempotent: the whole point.
func (g *GCounter) Merge(other *GCounter) {
for id, c := range other.counts {
if c > g.counts[id] {
g.counts[id] = c
}
}
}Why the maximum, and not the sum, on merge? Because a replica’s own slot is monotonically increasing and authoritative for that replica. If A has seen B’s slot at 2 and later at 5, taking the max keeps the freshest known value; summing would double-count the 2. This is exactly the join in the lattice of “vectors of monotonic counters.”
A quick convergence demo:
a := NewGCounter("A")
b := NewGCounter("B")
a.Increment(5) // A counts 5 locally
b.Increment(4) // B counts 4 locally, concurrently
a.Merge(b) // exchange state…
b.Merge(a) // …in either order
// Both now read 9, regardless of merge order or duplicate merges.
fmt.Println(a.Value(), b.Value()) // 9 9PN-Counter (increment and decrement)
G-Counters can’t decrement; subtracting would break monotonicity and the lattice falls apart. The fix is delightfully simple: a PN-Counter is two G-Counters, one tracking all increments (P), one tracking all decrements (N). The value is sum(P) − sum(N). Each sub-counter only grows, so each is a valid CRDT, and a pair of CRDTs merged component-wise is itself a CRDT.
// PNCounter supports increment and decrement via two grow-only counters.
type PNCounter struct {
p *GCounter // increments
n *GCounter // decrements
}
func NewPNCounter(id string) *PNCounter {
return &PNCounter{p: NewGCounter(id), n: NewGCounter(id)}
}
func (c *PNCounter) Increment(x uint64) { c.p.Increment(x) }
func (c *PNCounter) Decrement(x uint64) { c.n.Increment(x) }
// Value can be negative, so return a signed int.
func (c *PNCounter) Value() int64 {
return int64(c.p.Value()) - int64(c.n.Value())
}
func (c *PNCounter) Merge(other *PNCounter) {
c.p.Merge(other.p)
c.n.Merge(other.n)
}This “compose smaller CRDTs into bigger ones” move is the most important pattern in the whole field. Maps of counters, lists of registers, registers of sets: almost every rich CRDT is built by composition, and composition preserves the SEC guarantee for free.
2. Registers
A register holds a single replaceable value (a title, a status, a profile field). The hard question is what to do when two replicas assign different values concurrently. There are two honest answers.
LWW-Register (last-writer-wins)
Attach a timestamp to every write; on merge, the highest timestamp wins. Ties are broken by replica ID so the outcome is fully deterministic (never rely on wall-clock ties resolving themselves). Use a logical clock (a Lamport timestamp) rather than wall-clock time if you can, to avoid clock-skew surprises.
// LWWRegister keeps the value with the highest (timestamp, replicaID) pair.
type LWWRegister[T any] struct {
value T
ts uint64 // logical clock
id string // tiebreaker
}
func (r *LWWRegister[T]) Set(v T, ts uint64) {
if ts > r.ts || (ts == r.ts && r.id != "") {
r.value, r.ts = v, ts
}
}
func (r *LWWRegister[T]) Value() T { return r.value }
func (r *LWWRegister[T]) Merge(other LWWRegister[T]) {
// Compare on (ts, id) so ties resolve deterministically everywhere.
if other.ts > r.ts || (other.ts == r.ts && other.id > r.id) {
r.value, r.ts, r.id = other.value, other.ts, other.id
}
}LWW is simple and cheap, and it’s exactly right for fields where “the most recent edit should win” is the real intent. Its honest downside: it discards the losing concurrent write. If two people set a document title at the same instant, one edit silently vanishes. That’s a deliberate, declared trade-off, not a bug, but you must want it.
MV-Register (multi-value)
When you’d rather not throw a concurrent write away, the multi-value register keeps all concurrently-assigned values and hands the set to the application to resolve (think Amazon Dynamo’s “your cart has two versions, here are both”). It uses version vectors to tell concurrent writes (keep both) apart from superseding writes (a later write that causally follows an earlier one replaces it). Version vectors are the same per-replica-counter idea as the G-Counter, used here to capture causality:
// A version vector maps replicaID -> last seen counter.
type VV map[string]uint64
// dominates reports whether a >= b on every entry (a saw everything b saw).
func dominates(a, b VV) bool {
for id, bc := range b {
if a[id] < bc {
return false
}
}
return true
}
type valued[T any] struct {
val T
vv VV
}
// MVRegister keeps every value whose version vector is not dominated by another.
type MVRegister[T any] struct {
entries []valued[T]
}
// Values returns all concurrent "winners" for the application to reconcile.
func (r *MVRegister[T]) Values() []T {
out := make([]T, 0, len(r.entries))
for _, e := range r.entries {
out = append(out, e.val)
}
return out
}
// Merge keeps only entries that no other entry strictly dominates.
func (r *MVRegister[T]) Merge(other MVRegister[T]) {
all := append(append([]valued[T]{}, r.entries...), other.entries...)
var kept []valued[T]
for i, e := range all {
dominated := false
for j, f := range all {
if i != j && dominates(f.vv, e.vv) && !dominates(e.vv, f.vv) {
dominated = true
break
}
}
if !dominated {
kept = append(kept, e)
}
}
r.entries = kept
}MV-Registers lose nothing, but they push the conflict back to you. That’s the recurring tension in register design: lose data deterministically (LWW), or keep everything and resolve later (MV).
3. Sets
Sets are where CRDT design gets genuinely interesting, because add and remove are not naturally commutative, and making them so is the art.
G-Set and 2P-Set
A G-Set (grow-only set) supports only add; merge is union. It’s the canonical CRDT from Part 1 and needs no metadata, but you can never remove anything.
A 2P-Set (two-phase set) bolts on removal with a second G-Set of “tombstones.” An element is present if it’s in the add-set and not in the remove-set. The fatal limitation: once removed, an element can never be re-added: its tombstone is permanent. That’s rarely what users want.
type TwoPhaseSet[T comparable] struct {
adds map[T]struct{}
removes map[T]struct{}
}
func (s *TwoPhaseSet[T]) Add(e T) { s.adds[e] = struct{}{} }
func (s *TwoPhaseSet[T]) Remove(e T) { s.removes[e] = struct{}{} } // permanent!
func (s *TwoPhaseSet[T]) Contains(e T) bool {
_, added := s.adds[e]
_, removed := s.removes[e]
return added && !removed
}
func (s *TwoPhaseSet[T]) Merge(o *TwoPhaseSet[T]) {
for e := range o.adds {
s.adds[e] = struct{}{}
}
for e := range o.removes {
s.removes[e] = struct{}{}
}
}OR-Set (observed-remove set)
The OR-Set is the one you actually want, and it’s the workhorse behind real-world set and map CRDTs. It lets you add, remove, and re-add freely, with clean add-wins semantics under concurrency: if one replica removes an element while another concurrently adds it, the element stays.
The mechanism: every add tags the element with a unique token. remove doesn’t delete the element; it records the specific tags it has observed so far. An element is present if it has at least one tag that hasn’t been removed. A concurrent add creates a fresh tag the remover never saw, so that add survives.

import "github.com/google/uuid"
type tag struct {
replica string
token string
}
// ORSet supports add, remove, and re-add with add-wins concurrency semantics.
type ORSet[T comparable] struct {
id string
live map[T]map[tag]struct{} // element -> set of unremoved tags
}
func NewORSet[T comparable](id string) *ORSet[T] {
return &ORSet[T]{id: id, live: make(map[T]map[tag]struct{})}
}
// Add stamps the element with a brand-new unique tag.
func (s *ORSet[T]) Add(e T) {
if s.live[e] == nil {
s.live[e] = make(map[tag]struct{})
}
s.live[e][tag{s.id, uuid.NewString()}] = struct{}{}
}
// Remove drops exactly the tags this replica has observed for e.
// Tags created concurrently elsewhere are untouched, so they win.
func (s *ORSet[T]) Remove(e T) {
delete(s.live, e)
}
func (s *ORSet[T]) Contains(e T) bool {
return len(s.live[e]) > 0
}
// Merge unions the surviving tags per element.
func (s *ORSet[T]) Merge(o *ORSet[T]) {
for e, tags := range o.live {
if s.live[e] == nil {
s.live[e] = make(map[tag]struct{})
}
for t := range tags {
s.live[e][t] = struct{}{}
}
}
}Implementation note. The version above keeps only live tags, which is the easiest model to read. Production OR-Sets track an explicit set of removed tags (tombstones) so that a remove can be replicated and merged like any other operation, rather than relying on
delete. The semantics are identical (add-wins), but tombstone bookkeeping is what makes remove itself convergent across replicas. Garbage-collecting those tombstones safely is one of the genuinely hard parts of shipping CRDTs, and we’ll come back to it in Part 3.
The behavior to internalize: across every ordering and duplication of a given set of add/remove operations, an OR-Set converges to exactly one value. That determinism is the SEC guarantee from Part 1, made concrete.
4. Sequences: the hard one
Counters, registers, and sets cover a lot of ground, but collaborative text needs an ordered list where concurrent inserts at the same position must (a) all survive and (b) end up in the same order on every replica. You can’t use array indices: if A inserts at index 2 while B deletes at index 1, A’s index now points at the wrong character on B’s replica.
The family of solutions (RGA, Replicated Growable Array; Logoot; Treedoc; and the modern variants inside Yjs and Automerge) shares one idea: give every element a globally unique, densely orderable identifier instead of a positional index. An insert references the ID of the element it follows; ordering is by these stable IDs, so concurrent inserts interleave deterministically and deletes just tombstone an element without shifting anyone else’s identifiers.
A minimal RGA-style sketch:
// Each character gets a unique, totally-ordered ID. Inserts point at the
// ID they follow; the list is kept sorted by ID, so all replicas agree.
type elemID struct {
ts uint64 // logical clock
id string // replica ID, breaks ties
}
type node[T any] struct {
id elemID
value T
deleted bool // tombstone instead of physical removal
}
type RGA[T any] struct {
nodes []node[T] // kept ordered by (after-link, then id)
}
// less gives a total order over IDs so every replica sorts identically.
func less(a, b elemID) bool {
if a.ts != b.ts {
return a.ts < b.ts
}
return a.id < b.id
}The full insertion/interleaving logic is more than a snippet can carry honestly; it’s the part real libraries spend most of their cleverness on, and it’s why you should almost always reach for Yjs, Automerge, or Loro rather than hand-rolling a sequence CRDT. But the shape is the same lattice story: unique IDs that only get added (monotonic), deletes that only set a tombstone flag (monotonic), and a merge that unions nodes and re-sorts. Climb the lattice, take the join, converge.
The pattern behind all of them
Step back and the same three moves appear in every type:
- Replace destructive updates with monotonic ones. Don’t overwrite: add to a per-replica slot (counters), append a timestamped value (registers), or add a uniquely-tagged element (sets). State only ever grows in the lattice.
- Make concurrency explicit with metadata. Per-replica counters, logical timestamps, version vectors, unique tags: each is a device for distinguishing “this happened after that” from “these happened concurrently.”
- Define merge as the join. Maximum, union, dominance-filter, tag-union: whatever the least upper bound is for that lattice. Commutative, associative, idempotent, and therefore convergent.
Part 3 takes these primitives into the wild: the production libraries that implement them far better than we just did, the systems shipping CRDTs today, and an honest accounting of the costs: metadata growth, tombstone garbage collection, and the invariants CRDTs simply can’t enforce.
The Go above is written for clarity over micro-optimization; production CRDTs add delta-state encoding, compression, and tombstone GC. Merge semantics for the counter, register, and set types were validated for convergence against an executable model before publishing.