CRDTs from Scratch, Part 1: The Foundations
The intuition and the math behind Conflict-free Replicated Data Types: Strong Eventual Consistency, join semilattices, and the difference between state-based and operation-based replication.
A three-part series on Conflict-free Replicated Data Types. The distributed clocks series covers the causality model this series builds on. Part 1 builds the intuition and the theory; Part 2 implements the classic CRDTs in Go; Part 3 covers real-world use, libraries, and the limits.
The problem nobody can avoid
Build anything that runs in more than one place (a mobile app that works offline, a multi-region database, a collaborative editor, a shopping cart replicated across data centers), and you will eventually hit the same wall: two copies of the same data accepted different writes, and now you have to reconcile them.
The textbook answer is coordination. Pick a leader, take a lock, run consensus (Paxos, Raft), make everyone agree on an order before anything is allowed to commit. That works, and it gives you strong consistency. But coordination has a price the CAP theorem makes explicit: when the network partitions, a system that insists on a single agreed order must stop accepting writes on at least one side to stay consistent. For a checkout flow or an editor, “the app is read-only until the network heals” is often a worse outcome than a small, well-defined inconsistency.

CRDTs take the other branch of CAP. They keep accepting writes everywhere, all the time, even fully offline, and guarantee that once replicas can exchange their updates, they will converge to the same value with no coordination and no central arbiter. The trick is to design the data type so that merging is always safe, regardless of what happened where or in what order.
That last clause carries all the weight. Let’s pin it down.
What “CRDT” actually stands for
CRDT expands to Conflict-free Replicated Data Type. Read it backwards:
- It’s a data type: a counter, a set, a map, a list, a piece of text. It has an interface you program against.
- It’s replicated: every node holds a full copy and can read and write its own copy locally, with no round trip.
- It’s conflict-free, not because conflicts can’t happen (concurrent edits absolutely happen), but because the type defines a single, deterministic way to resolve every possible concurrent state. There is no “merge conflict” to hand back to a human or a server.
The formal goal CRDTs satisfy is Strong Eventual Consistency (SEC), defined by Shapiro, Preguiça, Baquero, and Zawirski in their 2011 paper that named the field. SEC strengthens ordinary eventual consistency with one extra promise:
Eventual delivery: every update eventually reaches every replica. Convergence (the strong part): any two replicas that have received the same set of updates are in the same state, immediately, without any further coordination round.
Plain eventual consistency only promises that replicas settle eventually; it doesn’t say they settle on the same thing, which is why systems like early Dynamo needed read-repair and application-level conflict resolution. SEC removes that ambiguity: same updates in, same state out, guaranteed by math.

The algebra that makes it work
Why can a CRDT promise convergence when a plain key-value store can’t? Because its merge operation is built on a small, rigid set of algebraic properties. For the most common family, state-based CRDTs, the merge function must be:
- Commutative:
merge(a, b) = merge(b, a). Order of merging doesn’t matter. - Associative:
merge(merge(a, b), c) = merge(a, merge(b, c)). Grouping doesn’t matter. - Idempotent:
merge(a, a) = a. Merging the same state twice changes nothing.
These three together mean a merge function is robust against everything a real network throws at it: messages arriving out of order (commutativity + associativity handle that), and messages arriving more than once (idempotence handles that). You don’t need exactly-once delivery, you don’t need ordered delivery, you don’t need to dedupe. Re-deliver an old state ten times and the result is identical.
A structure whose values can be combined by such an operation is a join semilattice: a partially ordered set in which any two elements have a least upper bound (their “join”, written ⊔). The merge function is that join. Every update moves a replica’s state monotonically “upward” in this lattice (never sideways, never down), and merging two states jumps to the smallest state that sits above both.
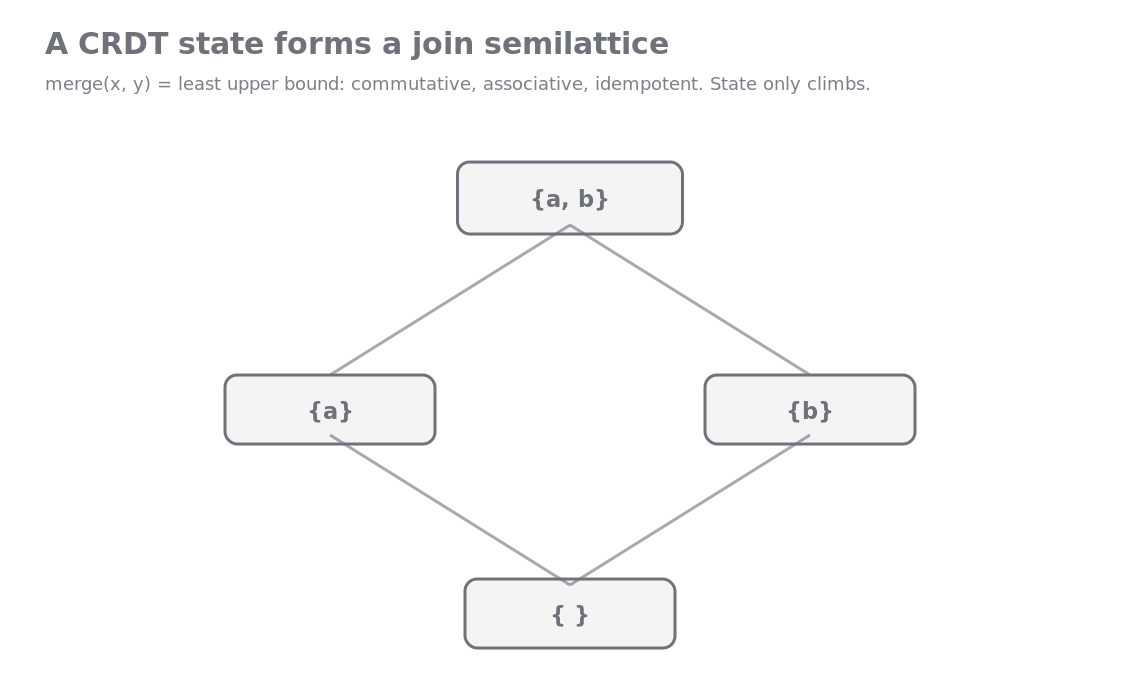
Concretely: model a grow-only set ordered by ⊆. The join of {a} and {b} is {a, b}: the smallest set containing both. Union is commutative, associative, and idempotent, so a grow-only set is automatically a CRDT. Most of Part 2 is just finding the right lattice for counters, registers, sets, and sequences so that their natural operations also become a monotonic climb with a well-defined join.
Two ways to replicate: state-based and operation-based
There are two dual strategies for getting updates from one replica to another. Both achieve SEC; they make opposite trade-offs about what travels over the wire and what the network must guarantee.
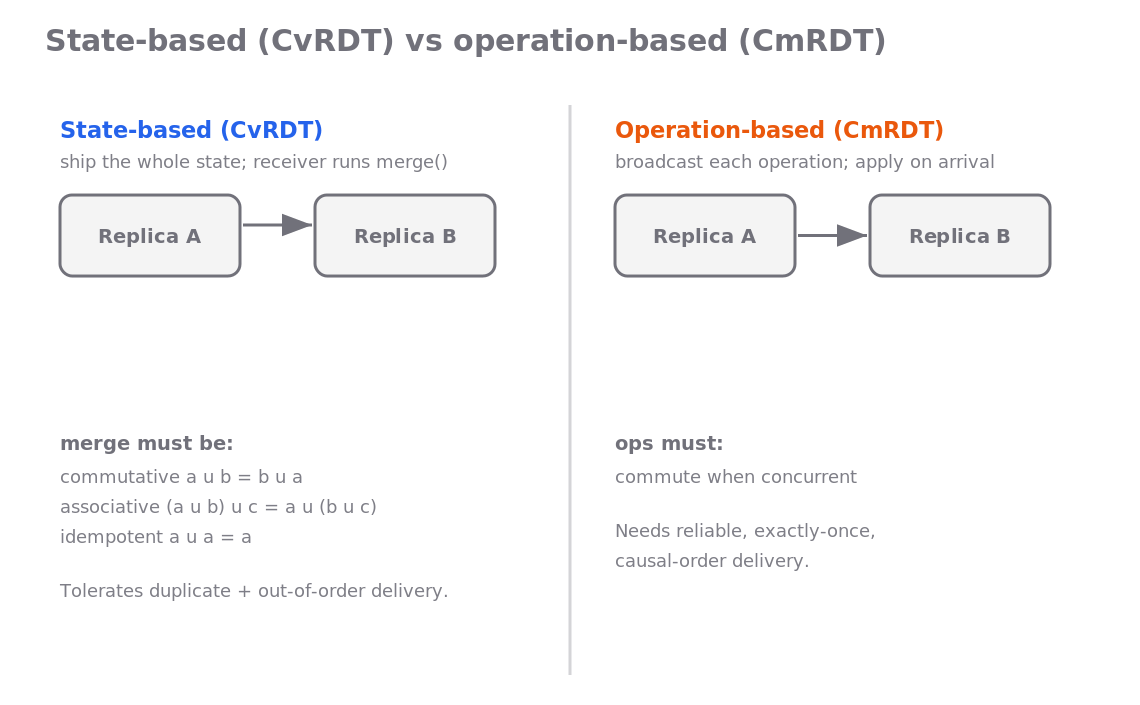
State-based (CvRDT, Convergent Replicated Data Type)
A replica applies updates locally, then periodically ships its entire state to a peer. The receiver folds it in with merge(). Because merge is commutative, associative, and idempotent, the transport can be almost anything: gossip, anti-entropy, an occasional full sync over a flaky link. Lost a message? The next full state contains everything the lost one did. Got a duplicate? Idempotence absorbs it.
The cost is payload size: naively you ship the whole object every time. Production systems shrink this with delta-state CRDTs, which send only the small piece of the lattice that changed while keeping the same merge guarantees. Riak’s distributed data types and many database-internal CRDTs are state-based.
Operation-based (CmRDT, Commutative Replicated Data Type)
Instead of shipping state, a replica broadcasts each operation (increment, add(x), insert(char)), and every replica applies it. Messages are tiny. The catch moves to the transport: operations must be delivered reliably, exactly once, and in causal order. You give up idempotence-for-free (applying increment twice really does increment twice), so the delivery layer has to do the deduplication and causal ordering that state-based merge handled for you. Concurrent operations still have to commute, but you no longer need them to be idempotent.
Op-based CRDTs power most collaborative editors, where broadcasting a one-character insert is far cheaper than shipping the whole document. The two models are formally equivalent in expressive power (anything you can build as a CvRDT you can build as a CmRDT and vice versa), so the choice is an engineering one about bandwidth versus transport guarantees.
| State-based (CvRDT) | Operation-based (CmRDT) | |
|---|---|---|
| What’s sent | Full (or delta) state | Individual operations |
| Merge requirement | Commutative, associative, idempotent | Concurrent ops commute |
| Network needs | Unreliable / unordered OK | Reliable, exactly-once, causal order |
| Message size | Larger (mitigated by deltas) | Small |
| Typical use | Databases, KV stores, gossip systems | Collaborative editors, real-time sync |
The properties you get, and the ones you don’t
CRDTs are sometimes oversold, so let me name what they don’t give you alongside what they do.
What CRDTs guarantee:
- Availability and partition tolerance. Every replica reads and writes locally, online or off. This is what “local-first” software is built on.
- Deterministic convergence (SEC). No central server decides the truth; the data type does. Two replicas with the same updates are byte-for-byte equivalent in value.
- No lost updates from merging. Merge never silently throws away a concurrent write the way last-writer-wins on a raw value does, unless you specifically chose a last-writer-wins CRDT, which makes that trade-off explicit.
What they don’t give you:
- Not invariants across keys. A CRDT converges each value, but it can’t enforce a global constraint like “this bank balance must never go negative” or “this seat is booked by exactly one person.” Those need coordination; CRDTs deliberately avoid coordination. Picking a CRDT means accepting that such invariants are not guaranteed.
- Not “the right answer,” only a consistent one. When two users concurrently set a title to different strings, a CRDT will pick one deterministically (or keep both), but it can’t know which the humans meant. Convergence is a syntactic guarantee, not a semantic one.
- Not free of metadata. Resolving concurrency deterministically requires remembering things: version vectors, unique tags, sometimes tombstones for deleted elements. That bookkeeping can outweigh the actual data if you’re not careful, a point we return to in Part 3.
Where we’re headed
The mental model to carry into Part 2 is this: a CRDT is a data type whose state lives in a join semilattice, whose updates only ever climb that lattice, and whose merge is the least upper bound. Get those pieces right and convergence is automatic; you’ve moved correctness out of your distributed-systems plumbing and into the type itself.
In Part 2 we’ll build the classic CRDTs in Go and watch the algebra turn into running code: grow-only and positive-negative counters, last-writer-wins and multi-value registers, the grow-only / two-phase / observed-remove sets, and finally a sequence CRDT for collaborative text. In Part 3 we’ll connect them to the real systems that ship them today (Yjs, Automerge, Loro, Redis, Riak), and talk frankly about when not to reach for a CRDT.
Further reading: Shapiro et al., “Conflict-free Replicated Data Types” (2011) and “A comprehensive study of CRDTs” (INRIA tech report, 2011); the curated resources at crdt.tech.